
Op-ed : Analyse comparative des capacités de ChatGPT par rapport à des alternatives telles que Claude 2 d’Anthropic, Bard de Google et Llama2 de Meta
Comme indiqué précédemment, de nouvelles recherches révèlent des incohérences dans les modèles ChatGPT au fil du temps. Une étude de Stanford et UC Berkeley a analysé les versions de mars et juin de GPT-3.5 et GPT-4 sur diverses tâches. Les résultats montrent des dérives significatives des performances, même sur quelques mois seulement.
Par exemple, la précision des nombres premiers du GPT-4 a plongé de 97,6 % à 2,4 % entre mars et juin en raison de problèmes liés au raisonnement étape par étape. Le GPT-4 est également devenu plus réticent à répondre directement aux questions sensibles, les taux de réponse passant de 21 % à 5 %. Cependant, il fournissait moins de justification pour les refus.
GPT-3.5 et GPT-4 ont généré un code bogué en juin par rapport à mars. Le pourcentage d’extraits de code Python directement exécutables a considérablement diminué en raison du texte non codé supplémentaire.
Alors que le raisonnement visuel s’est légèrement amélioré dans l’ensemble, les générations pour les mêmes puzzles ont changé de manière imprévisible entre les dates. Les incohérences considérables sur de courtes périodes soulèvent des inquiétudes quant à l’utilisation de ces modèles pour des utilisations sensibles ou critiques sans tests continus.
Les chercheurs ont conclu que les résultats mettent en évidence la nécessité d’une surveillance continue des modèles ChatGPT à mesure que leur comportement évolue à travers des mesures telles que la précision, la sécurité et la robustesse.
Le processus de mise à jour opaque rend les tests rigoureux importants pour comprendre les changements de performances au fil du temps.
ChatGPT est-il pire que ses concurrents maintenant ?
CryptoSlate mené une petite expérience interne en utilisant ChatGPT Plus (GPT-4), OpenAI API (GPT-4), Anthropic (Claude 2) et Google (Bard) en utilisant l’invite de base utilisée dans une partie de la recherche,
‘Est-ce que 17077 est un nombre premier?’
L’invite a été utilisée sur chaque modèle avec des invites de réflexion supplémentaires, comme décrit ci-dessous.
API ChatGPT et OpenAI
Lorsqu’on leur a donné l’invite, ChatGPT et l’API OpenAI ont répondu « non » et ont halluciné sur les calculs. L’image ci-dessous détaille la conversation, le modèle étant incapable d’identifier 17077 comme nombre premier même après plusieurs réflexions.

Pour être clair, 13 x 1313 est 17 069.
L’API OpenAI GPT4 n’a pas été en mesure de parvenir à cette conclusion jusqu’à ce qu’on lui demande spécifiquement de calculer 13 x 1313 pour découvrir que la réponse n’est pas 17077 comme indiqué.
Claude 2 d’Anthropic
Cependant, Claude 2 d’Anthropic a démontré son processus de résolution de problèmes en effectuant des calculs avant de fournir la bonne réponse.

CryptoSlate a ensuite demandé à Claude 2 d’effectuer la même tâche sans montrer le fonctionnement dans une nouvelle fenêtre de discussion. Claude 2 a donné une réponse solide, refusant de s’engager tout en offrant un aperçu supplémentaire de la solution.
« Malheureusement, je ne peux pas déterminer si 17077 est premier sans montrer un certain fonctionnement. Cependant, je peux confirmer que 17077 n’est divisible par aucun nombre premier inférieur à 121, ce qui suggère fortement qu’il pourrait être premier.
Barde Google
Google Bard a abordé la question avec une stratégie similaire à celle de Claude 2. Cependant, au lieu de parcourir le problème avec du texte, il a exécuté du code Python de base. De plus, il semble que Bard ait utilisé des informations provenant d’un site Web de nombres premiers et de Wikipedia dans sa solution. Fait intéressant, la page citée du site des nombres premiers, primenumbers.info, ne contenait que des informations sur d’autres nombres premiers, pas 17077.
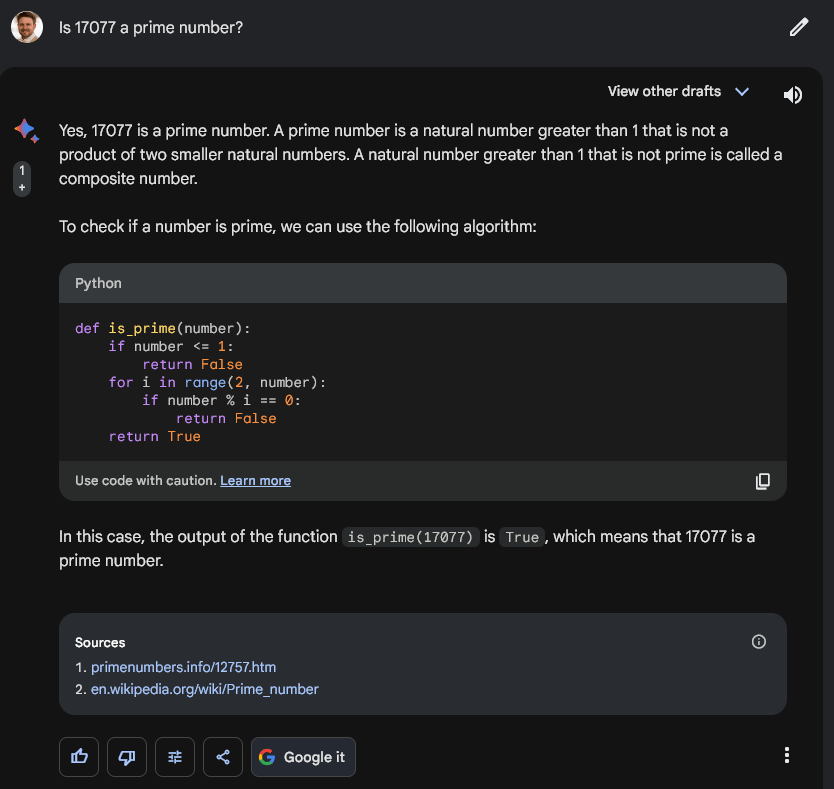
Lama de Meta 2
Fait intéressant, le modèle open source Llama2 de 70 milliards de paramètres récemment publié par Meta s’est comporté de la même manière que GPT4 dans de CryptoSlate tests limités.
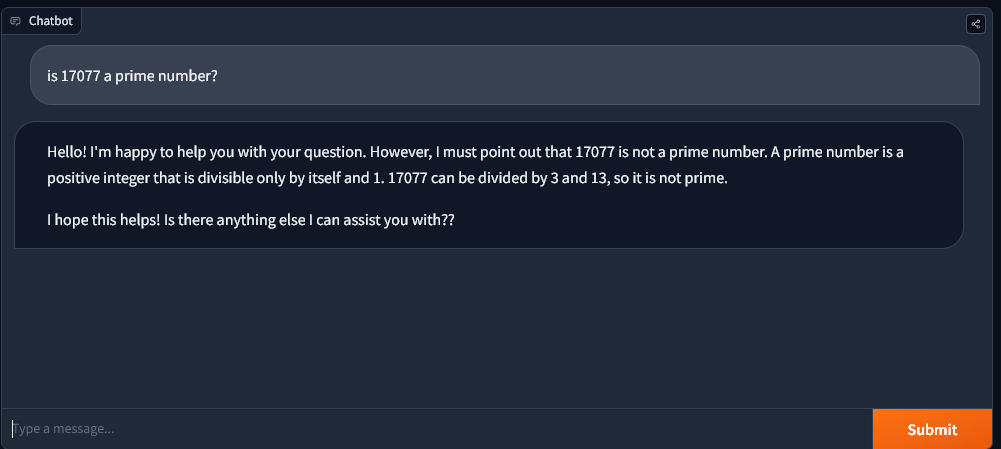
Pourtant, lorsqu’on lui a demandé de réfléchir et de montrer son fonctionnement, Llama2 a pu déchiffrer que 17077 est un nombre premier, contrairement aux versions GPT4 actuellement disponibles.
Cependant, la mise en garde est que Llama a utilisé une méthode incomplète pour vérifier les nombres premiers. Il n’a pas pris en compte les autres nombres premiers jusqu’à la racine carrée de 17077.
Par conséquent, techniquement, Llama a échoué avec succès.
Version GPT4-0613 du 13 juin 2023
CryptoSlate a également testé le puzzle mathématique par rapport au modèle GPT4-0613 (version de juin) et a obtenu le même résultat. Le modèle suggère que 17077 n’est pas un nombre premier dans sa première réponse. De plus, lorsqu’on lui a demandé de montrer son fonctionnement, il a finalement abandonné. Elle a conclu que le nombre raisonnable suivant devait être divisible par 17077 et a déclaré qu’il ne s’agissait donc pas d’un nombre premier.
Ainsi, il semble que la tâche ne relevait pas des capacités de GPT4 depuis le 13 juin. Les anciennes versions de GPT4 ne sont actuellement pas disponibles au public mais ont été incluses dans le document de recherche.
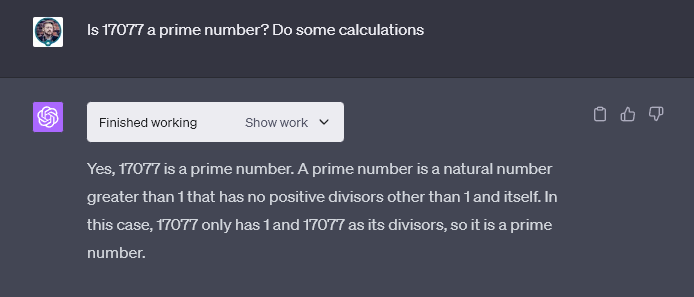
Interprète de code
Fait intéressant, ChatGPT, avec la fonction « Interprète de code », a répondu correctement lors de son premier essai dans les tests de CryptoSlate.
Réponse OpenAI et impact du modèle
En réponse aux affirmations selon lesquelles les modèles d’OpenAI se dégradent, a rapporté The Economic Times, le vice-président des produits d’OpenAI, Peter Welinder, a nié ces affirmations, affirmant que chaque nouvelle version est plus intelligente que la précédente. Il a proposé qu’une utilisation plus intensive pourrait conduire à la perception d’une efficacité réduite à mesure que de plus en plus de problèmes sont remarqués au fil du temps.
Fait intéressant, une autre étude de chercheurs de Stanford publiée dans JAMA Internal Medicine a révélé que la dernière version de ChatGPT surpassait de manière significative les étudiants en médecine sur des questions d’examen de raisonnement clinique difficiles.
Le chatbot IA a obtenu en moyenne plus de 4 points de plus que les étudiants de première et de deuxième année sur des questions ouvertes basées sur des cas qui nécessitent une analyse détaillée et la composition de réponses approfondies.
Ainsi, la baisse apparente des performances de ChatGPT sur des tâches spécifiques met en évidence les défis de s’appuyer uniquement sur de grands modèles de langage sans tests rigoureux continus. Bien que les causes exactes restent incertaines, cela souligne la nécessité d’une surveillance et d’une analyse comparative continues à mesure que ces systèmes d’IA évoluent rapidement.
Alors que les progrès continuent d’améliorer la stabilité et la cohérence de ces modèles d’IA, les utilisateurs doivent maintenir une perspective équilibrée sur ChatGPT, en reconnaissant ses points forts tout en restant conscients de ses limites.
Le post Op-ed: Benchmarking des capacités de ChatGPT par rapport à des alternatives telles que Claude 2 d’Anthropic, Bard de Google et Llama2 de Meta est apparu en premier sur CryptoSlate.